Try Fine-Tuning LLMs at Home
practice fine-tuning with LLaMA.
 figure1: A cute lama, generated by Flux 1.1 pro
figure1: A cute lama, generated by Flux 1.1 pro
Intro
In this post, we are going to briefly understand and practice LLMs fine-tuning.
What you need:
- PC
- one of the following AI accelerators:
- GPU, probably RTX 20 series or higher
- Cloud computing service like Colab or AWS instance
- Python, recommended a virtual environment
Index
- What is fine-tuning? why do we need to do that?
- What should we know before try fine-tuning?
- LoRA
- Quantization
- Batch size and gradient accumulation
- Try fine-tuning
- What do we do?
- Fine-tuning code
- Loss graphs
- Inference test
- Conclusion
- Other informative posts
- References
Update
- 2024-12-06: Updated section 3 and 4
1. What is fine-tuning? why do we need to do that?
Fine-tuning is not the only concept in language models area, but let us concentrate on this domain.
Companies like OpenAI, META, Google and Microsoft have released their own large language models. Such models are quite intelligent and can handle general tasks like Q&A, summary, classification, etc. in common sense.
However, even those state-of-the-art models are not perfect to some specific tasks or domains where they have never experienced. For example, if one model was not trained on medical data, it cannot be used as medical assistant. Also, in case of LLaMA 3, the large language model META AI, it only supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai officially. Then we can easily expect that LLaMA is not good at Japanese or Korean as much as officially supported languages. Beside, for image+text applications, English is the only language supported by multimodal LLaMA.
But training a LLM from scratch is very very complicated and expensive work, and furthermore, some big-tech enterprises released their model as free. i.e., by choosing pre-trained open-source model, individuals or small companies can save their resources. So what we need to do is just pick a model understanding common knowledges and tune the model for our own tasks.
2. What should we know before try fine-tuning?
You can skip this part, but before starting fine-tuining immediately, let us understand the following few keypoints:
- LoRA and its rank and alpha options
- Quantizaion
- Batch and gradient accumulation
Also my previous posts about Transformer and large language models would be helpful.
LoRA
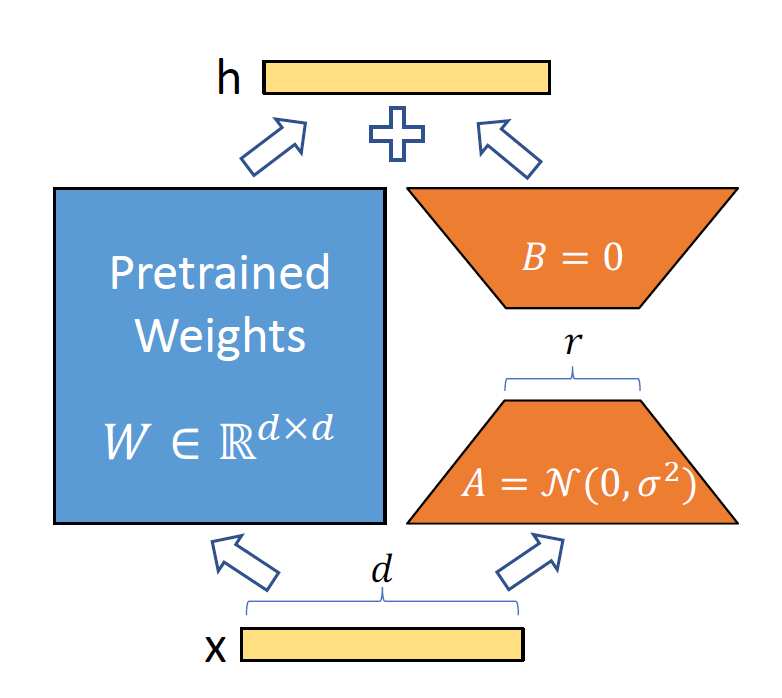 figure2: LoRA mechanism (source: “Lora: Low-rank adaptation of large language models. (2021)”)
figure2: LoRA mechanism (source: “Lora: Low-rank adaptation of large language models. (2021)”)
Fine-tuning means training a model to another dataset for a downstream task after pre-training. However “Scaling Laws for Neural Language Models (2020)” found the scaling law that the model scale is the most important feature in performance than others like data amount, training steps, and model shape. So it is hard to train all the weights of LLMs because the sizes are usually bigger than 1 billion.
In 2021, Hu, Edward J., et al. introduced LoRA technique. 1 This technique freezes the original parameters of a LLM and adds weight matrices as adapter. So this is a kind of Parameter-Efficient Fine-tuning. In detail, for an original weights matrix \(W\), LoRA method attachs additional trainable matrix \(\Delta W\) with rank \(r\) and scaling factor \(\alpha\) like \[\begin{gathered} W'x = (W + \frac{\alpha}{r}\Delta W) x, \newline \text{with} \quad \Delta W = B \cdot A \quad \text{for} \quad W, \Delta W \in \mathbb{R}^{(d,d)}, B \in \mathbb{R}^{(d,r)}, A \in \mathbb{R}^{(r,d)} \quad \text{where} \quad r << d, \end{gathered}\]
\(x\) is an input representative vector.
Also, the low-rank matrix \(\Delta W = BA\) has rank at most \(r\), i.e., there are at most \(r\) linearly independent vectors. It can be factorized as a sum of \(r(<<d)\) rank-1 matrices using outer products of vectors. (This is conceptually similar to how low-rank approximations are used in SVD, though LoRA uses directly learnable matrices \(B\) and \(A\) rather than decomposing \(W\).)
So we need to optimize \(r\) and \(\alpha\) since those are related to learning capacity and regulator of the LoRA adapter.
The benefits of LoRA are came from:
- Efficiency, because we need to only train and use \(2 \times r \times d\) weights instead of \(d^2\).
- Flexibility, because we need to only save and shift the LoRA weights adapter.
Quantization
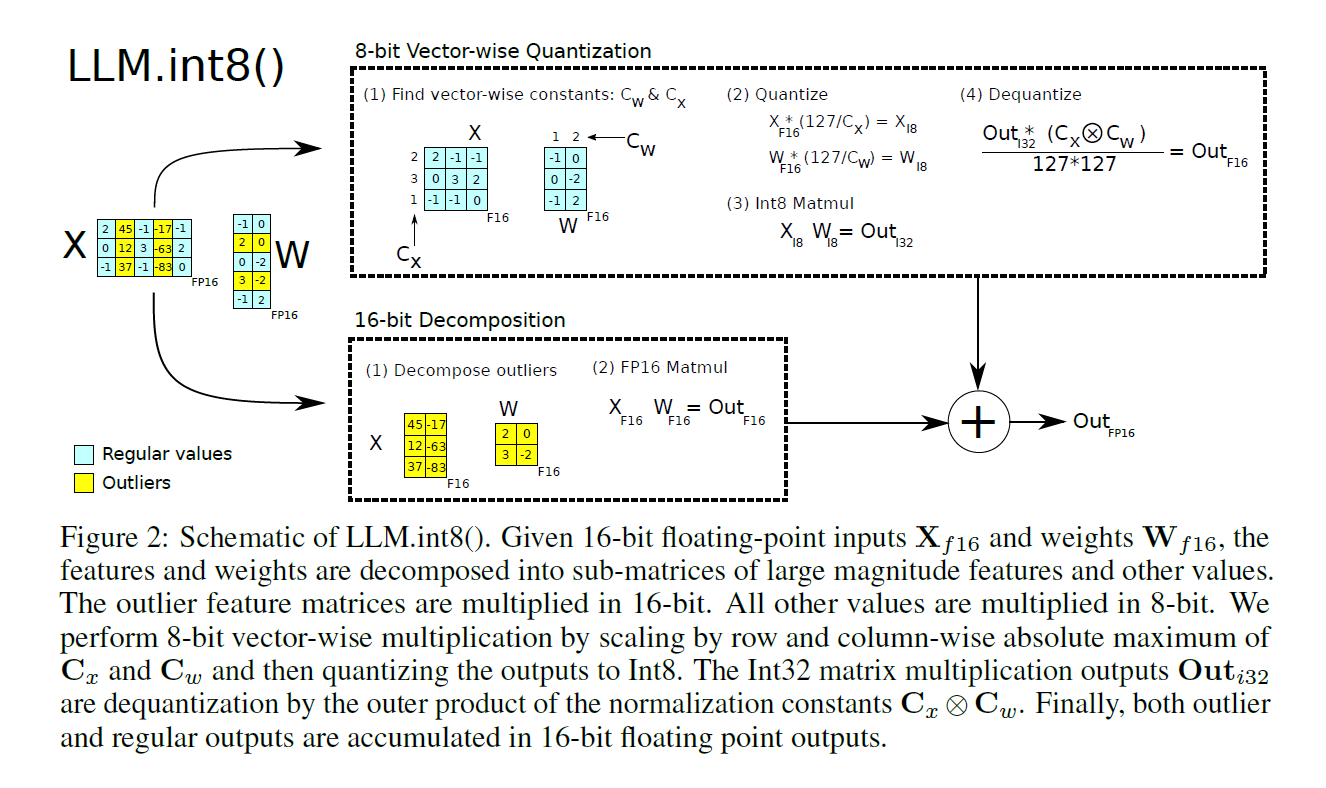 figure3: Quantization method in LLM.int8() paper
figure3: Quantization method in LLM.int8() paper
Many DL model parameters are stored as one of following formats: ‘standard single-precision floating-point form’, ‘standard half-precision floating-point form’, and ‘brain floating-point form’ a.k.a fp32, fp16, and bf16 respectively. For example, each number expressed in the float32 data type requires 32 bit of information quantities. However, because of the large scale of language models, this causes computationally intensive training and slow inference. I don’t know the latest research about quantization methods, but the concept of quantization is similar to clustering. Given parametric data, we group them into several points by mapping floating-point values to discrete levels (e.g., integers). We may use scaling to transform the grouped floating numbers into a smaller integer representation, while being aware of outliers. 2
Subsequently, the model parameters are downsized from float32 to int8, int4, or even more compact forms, enabling faster inference and reduced hardware requirements. 3, 4
Batch and Gradient Accumulation
 figure4: Simple batch training and the corresponding gradient accumulation (source: https://unsloth.ai/blog/gradient)
figure4: Simple batch training and the corresponding gradient accumulation (source: https://unsloth.ai/blog/gradient)
Batch size, precisely mini-batch size, is one of practical options in fine-tuning. Larger batch size tends to stablize training and boost convergence, but also takes a lot of GPU memory. Fortunately, Hugging Face transformers library with PEFT or Unsloth supports gradient accumulation feature. If we use gradient accumulation, the optimizer does not update the weights immediately right after loss calculation for each batch. Instead, it stacks loss values until reaching given gradient_accumulation_steps, averages the loss sum ‘properly’, and then update the weights. So this batch_size \(\times\) gradient_accumulation_steps equals to actual larger batch size.
Therefore, this trick enables to mimic larger and more effective batch training while reducing VRAM usage. 5
3. Try fine-tuning
There is no only one way to fine-tune LLMs.
You can use web-based services such as OpenAI or Kaggle without a bunch of complicated codelines.
You can also do it free by downloading models to your computer with Hugging Face API.
In case of Hugging Face, There are also some various packages and open-sources compatible to Hugging Face: PEFT, TRL, Unsloth, Qwen etc., and each library is not exclusive to others.
Unsloth is a novel open-source Python library for efficent fine-tuning of LLMs. The brothers, who developed the library, introduce that Unsloth is faster and more memory-efficient than the original implements of Hugging Face. Also they manually scripted autograd instead of torch autograd and rewrote OpenAI Triton kernels. Although training on multi-GPU is not free, but it is no matter for individuals or students.
What do we do?
If you want to fine-tune an open-source LLM on your own task, it might be insufficient to train it immediately on your task specific dataset. There are several reasons:
- Most LLMs are mainly exposed to English data and may not have common sense about the other cultures.
- If you want to prevent overfitting, you must not reuse the data too much time during fine-tuning. In this case, Scaling up the dataset would be helpful, but it is hard to obtain such well-refined dataset.
To handle this situation, there is a solution: Continued Pre-Training.
Then what is continued pre-training? For example, if I want to make a Korean counseling chatbot from LLaMA, first I train it dataset with full of Korean context and culture like Korean wikipedia pages, then fine-tune it toward my own counseling-task dataset.
The other main ideas distinct to ordinary LoRA fine-tuning are well explained in the official blog post of Unsloth, but here is the summary:
- Train input and output embeddings too (embed_tokens and lm_head), but use different learning rate.
- Use rank stablized LoRA. 6
Therefore I chose Unsloth and LLaMA to try fine-tuning in this post. Visit my github repo for the full version code.
Fine-tuning code
I slightly reformed the original code on my purpose, but it is just for validation, inference, saving and loading. The mainstream is almost equivalent to the original.
When I tried batch_size = 2, VRAM usage was less than 10GB, probably 7~9 during fine-tuning. This reduced memory consuming was really beneficial.
Build environment
Install deep learning packages.
!pip install "torch==2.4.0" "xformers==0.0.27.post2" tensorboard pillow torchvision accelerate huggingface_hub transformers datasets accelerate unsloth
Import libraries
import torch
from transformers import (
AutoTokenizer,
TextStreamer,
)
from unsloth import (
FastLanguageModel,
is_bfloat16_supported,
unsloth_train,
UnslothTrainer,
UnslothTrainingArguments,
)
from datasets import load_dataset
# Hugging Face repository settings
HF_write_token = "your_token"
user_name = "your_id"
seed = 42
Set important hyperparameters
I used \(alpha = 2 \times rank\) according to this paper. 7
# Important hyperparameters
max_seq_length = 2048
load_in_4bit = True
BATCH_SIZE = 8
rank = 128
alpha = rank*2
Load model for CPT
base_model_path = "unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit"
# Initialize model and tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=base_model_path,
max_seq_length=max_seq_length,
dtype=torch.bfloat16,
load_in_4bit=load_in_4bit,
)
# Configure CPT LoRA
model = FastLanguageModel.get_peft_model(
model,
r = rank, # LoRA rank. Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
"embed_tokens", "lm_head",], # Add for continual pretraining
lora_alpha = alpha, # LoRA scaling factor alpha
lora_dropout = 0.0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = seed,
use_rslora = True, # Unsloth supports rank stabilized LoRA
loftq_config = None, # And LoftQ
)
model.print_trainable_parameters() # the number of trainable weights increase when using "embed_tokens" and "lm_head".
Text data formatting for CPT
You can also use unsloth.get_chat_template function to get the correct chat template. It supports zephyr, chatml, mistral, llama, alpaca, vicuna, vicuna_old, phi3, llama3 and more. See example page.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
# Wikipedia provides a title and an article text.
wikipedia_prompt = """위키피디아 기사
### 제목: {}
### 기사:
{}"""
titles = examples["title"]
texts = examples["text"]
outputs = []
for title, text in zip(titles, texts):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = wikipedia_prompt.format(title, text) + EOS_TOKEN
outputs.append(text)
return { "text" : outputs, }
Prepare data for CPT
You can change the data to your own language or domain relevant dataset.
# Load and prepare dataset
dataset = load_dataset("wikimedia/wikipedia", "20231101.ko", split = "train", )
# Format dataset
train_set = dataset.map(formatting_prompts_func, batched = True,)
print(train_set[0:2])
Set CPT trainer and run
unsloth_train(trainer) codeline handles the gradient accumulation bug. Refer to the official post.
# Define trainer
trainer = UnslothTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_set,
dataset_text_field="text",
max_seq_length=max_seq_length,
args = UnslothTrainingArguments(
per_device_train_batch_size=BATCH_SIZE, # training batch size
gradient_accumulation_steps = 2, # by using gradient accum, we updating weights every: batch_size * gradient_accum_steps
# Use warmup_ratio and num_train_epochs for longer runs!
warmup_ratio = 0.1,
num_train_epochs = 1,
# Select a 2 to 10x smaller learning rate for the embedding matrices!
learning_rate = 5e-5,
embedding_learning_rate = 1e-5,
# validation and save
logging_steps=100,
save_strategy='steps',
save_steps=5000,
save_total_limit=3,
save_safetensors=True,
# dtype
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear", # try "cosine"
seed = seed,
output_dir = "outputs/CPT", # Directory for output files
report_to="tensorboard", # Reporting tool (e.g., TensorBoard, WandB)
),
)
trainer_stats = unsloth_train(trainer)
Save CPT LoRA (optional)
# Save trained model locally and to Hugging Face Hub
repo_name = "CPT_LoRA_Llama-3.1-8B-Instruct-bnb-4bit_wikipedia-ko"
CPT_path = f"{user_name}/{repo_name}"
# Local
model.save_pretrained(repo_name)
tokenizer.save_pretrained(repo_name)
# Online
model.push_to_hub(
CPT_path,
tokenizer=tokenizer,
private=True,
token=HF_write_token,
save_method = "lora", # You can skip this. Default="merged_16bit" prabably. Also available "merged_4bit".
)
tokenizer.push_to_hub(
CPT_path,
private=True,
token=HF_write_token,
)
Load model for Instruction Fine-Tuning (IFT)
For flexible utilization of CPT only LoRA, I just halted here to save the CPT checkpoints. However, since seamless resumption from CPT to IFT is not supported, we need to try either (1) ordinary fine-tuning without embedding learning or (2) making another LoRA adapter same as the above CPT process.
I’ll choose the 1st way with reference to the official document: https://docs.unsloth.ai/basics/continued-pretraining
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=CPT_path,
max_seq_length=max_seq_length,
dtype=torch.bfloat16,
load_in_4bit=load_in_4bit,
)
model.print_trainable_parameters()
Text data formatting for IFT
# dataset formatting function
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(conversations):
alpaca_prompt = """다음은 작업을 설명하는 명령입니다. 요청을 적절하게 완료하는 응답을 작성하세요.
### 지침:
{}
### 응답:
{}"""
conversations = conversations["conversations"]
texts = []
for convo in conversations:
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(convo[0]["value"], convo[1]["value"]) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
Prepare data for IFT
Again, choose your own task-specific data.
alpaca_dataset = load_dataset("FreedomIntelligence/alpaca-gpt4-korean", split = "train")
alpaca_dataset = alpaca_dataset.train_test_split(test_size=0.1, shuffle=True, seed=seed) # Split dataset into train/validation sets
alpaca_train_set, alpaca_val_set = alpaca_dataset["train"], alpaca_dataset["test"]
alpaca_train_set = alpaca_train_set.map(formatting_prompts_func, batched = True,)
print(alpaca_train_set[0:2])
alpaca_val_set = alpaca_val_set.map(formatting_prompts_func, batched = True,)
print(alpaca_val_set[0:2])
Set trainer for IFT and run
trainer = UnslothTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = alpaca_train_set,
eval_dataset=alpaca_val_set,
dataset_text_field = "text",
max_seq_length = max_seq_length,
args = UnslothTrainingArguments(
per_device_train_batch_size=BATCH_SIZE, # training batch size
per_device_eval_batch_size=BATCH_SIZE, # validation batch size
gradient_accumulation_steps = 4, # by using gradient accum, we updating weights every: batch_size * gradient_accum_steps
# Use warmup_ratio and num_train_epochs for longer runs!
warmup_ratio = 0.1,
num_train_epochs = 3,
# Select a 2 to 10x smaller learning rate for the embedding matrices!
learning_rate = 5e-5,
embedding_learning_rate = 1e-5, # dummy option now
# validation and save
logging_steps=10,
eval_strategy='steps',
eval_steps=100,
save_strategy='steps',
save_steps=100,
save_total_limit=10,
save_safetensors=True,
# # callback
# load_best_model_at_end=True, # this option is only available when eval_strategy == save_strategy
# metric_for_best_model="eval_loss",
# greater_is_better=False,
# dtype
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
optim = "adamw_8bit",
weight_decay = 0.0,
lr_scheduler_type = "linear", # try "cosine"
seed = seed,
output_dir = "outputs/IFT", # Directory for output files
report_to="tensorboard", # Reporting tool (e.g., TensorBoard, WandB)
),
)
trainer_stats = unsloth_train(trainer)
Save IFT LoRA as simple safetensors and GGUF format
# Save trained model locally and to Hugging Face Hub as normal and quantized form
repo_name = "llama-3.1-8B_lora-IFT_CPT_alpaca-gpt4-ko"
IFT_path = f"{user_name}/{repo_name}"
# Local
model.save_pretrained(repo_name)
tokenizer.save_pretrained(repo_name)
# Online
model.push_to_hub(
IFT_path,
tokenizer=tokenizer,
private=True,
token=HF_write_token,
save_method = "lora", # also available "merged_16bit", "merged_4bit"
)
tokenizer.push_to_hub(
IFT_path,
private=True,
token=HF_write_token,
)
# GGUF / llama.cpp Conversion
repo_name = "llama-3.1-8B_lora-IFT_CPT_alpaca-gpt4-ko_GGUF"
IFT_GGUF_path = f"{user_name}/{repo_name}"
quantization_method = "q8_0" # or "f16" or "q4_k_m"
model.save_pretrained_gguf(repo_name, tokenizer, quantization_method=quantization_method)
model.push_to_hub_gguf(IFT_GGUF_path, tokenizer, save_method = "lora", quantization_method=quantization_method, private=True, token=HF_write_token)
Loss graphs
Before starting fine-tuning, I got a curiosity about how actually model scale and CPT affect the model performance. So I tried 2 simple experiments:
- Just trying IFT to LLaMA Instruct models 3.2-1B, 3.2-3B and 3.1-8B
- An ablation test comparing IFT vs. CPT+IFT
IFT 3.2-1B, 3.2-3B and 3.1-8B
# configs
rank = 16
epoch = 3
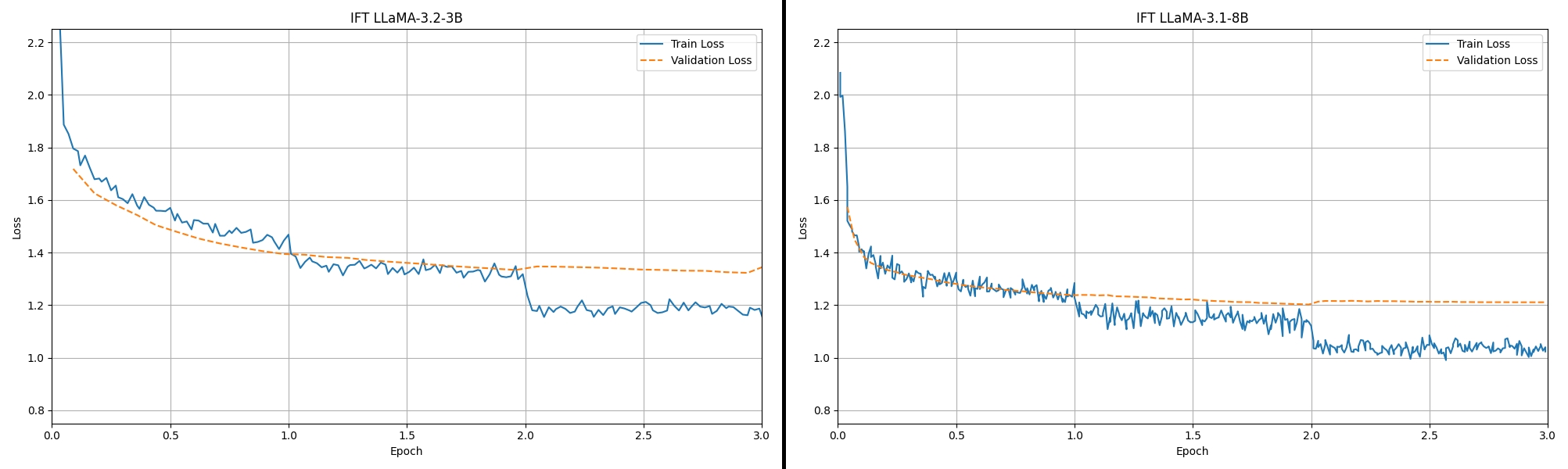 figure5: fine-tuning loss comparision between IFT 3.2-3B and IFT 3.1-8B (I lost the log data of 3.2-1B.)
figure5: fine-tuning loss comparision between IFT 3.2-3B and IFT 3.1-8B (I lost the log data of 3.2-1B.)
It seems like that the loss values are decreasing well, and trivially, the larger is the better. But there are some considerations.
The train-val loss gap is broaden at the beginning of epoch 3.
The loss values before the end of 2nd epoch are not sufficiently small enough when compared to the Unsloth official examples about English text data 1 and 2. Such examples even not trained in 1 full epoch, but only on a few steps.
(In this experiment, The rank number has no meaning, I just set up a wrong number.)
IFT vs. CPT+IFT
# configs
rank = 128
epoch = 2
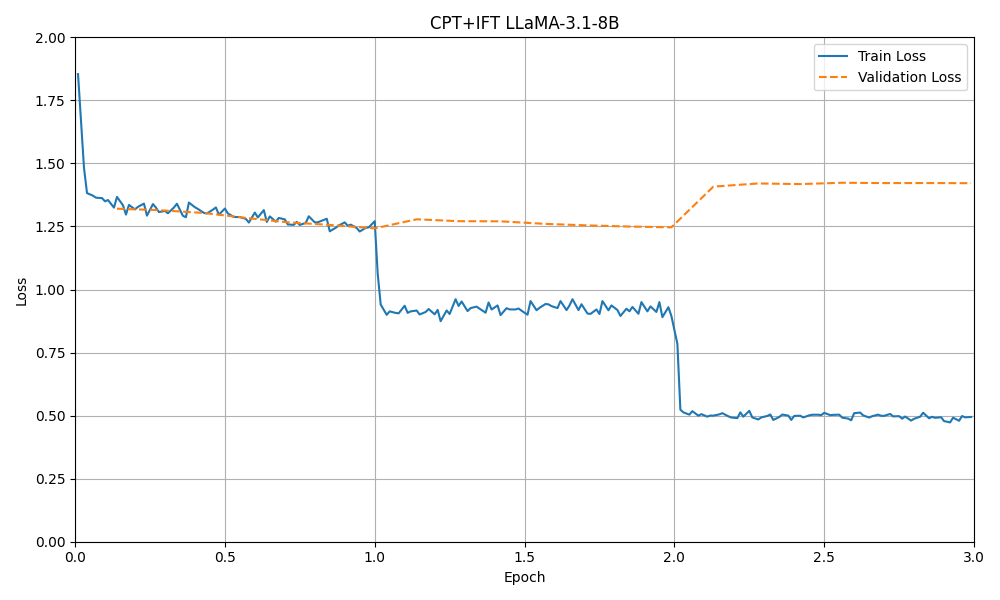 figure6: CPT+IFT 3.1-8B
figure6: CPT+IFT 3.1-8B
With the bigger rank, it is doubtful that overfitting has occured after epoch 2. Let us load the models trained up to epoch 2 and compare them.
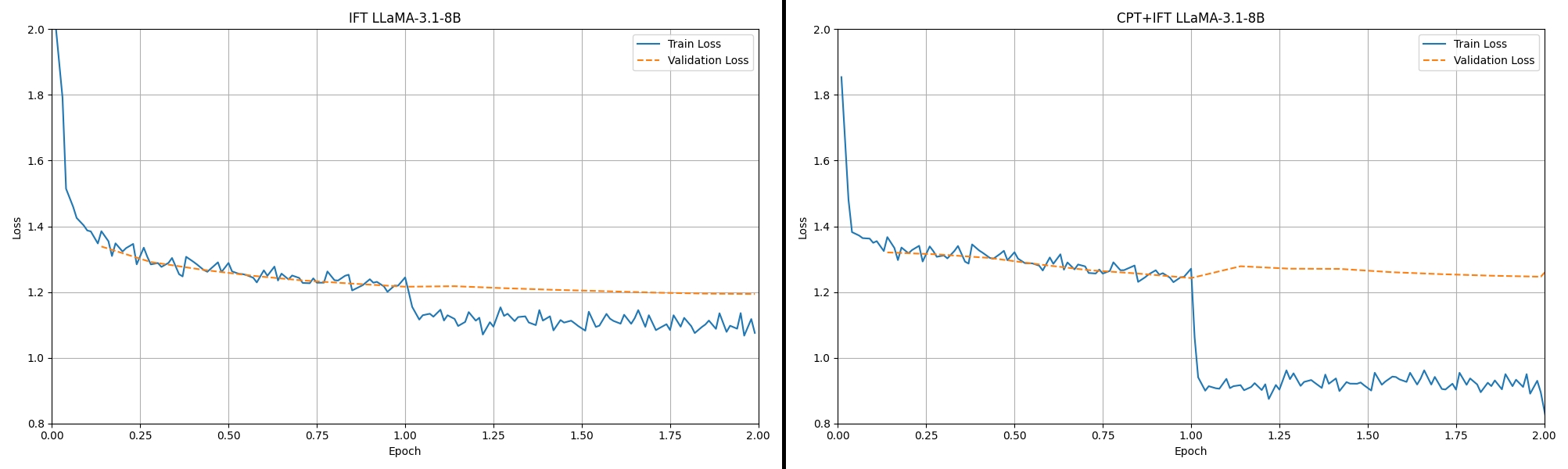 figure7: fine-tuning loss comparision between IFT 3.1-8B and CPT+IFT 3.1-8B
figure7: fine-tuning loss comparision between IFT 3.1-8B and CPT+IFT 3.1-8B
Despite the validation loss of the CPT+IFT is slightly worse, but the loss drop is very sharp right after epoch 1!
Another interesting observation is that the CPT model exhibits a kind of phase shift at the initial learning step, suggesting it may struggling with optimization in this early stage.
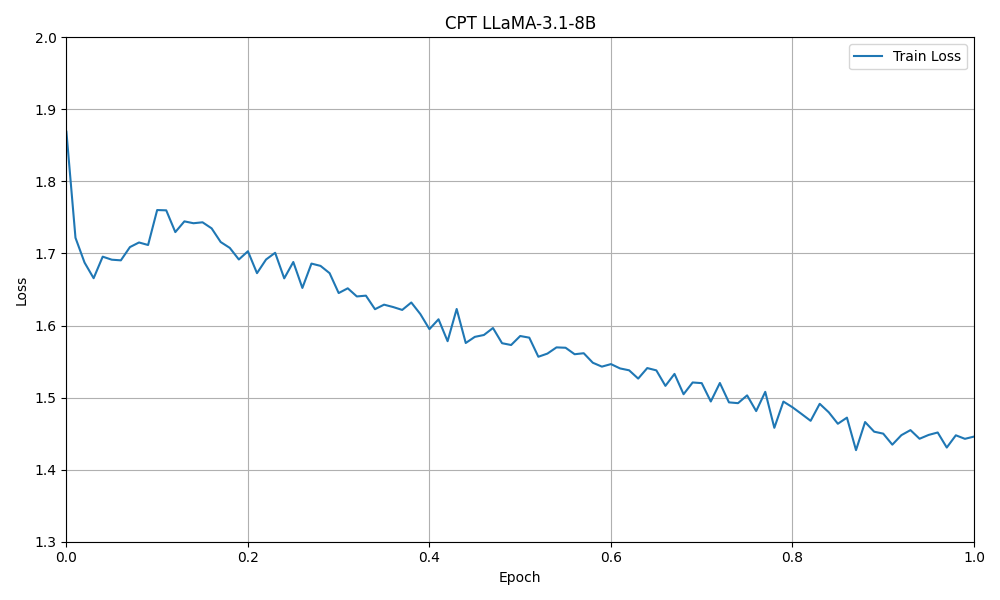 figure8: CPT 3.1-8B
figure8: CPT 3.1-8B
Inference test
Here are respective inference results with the same questions:
Q1. What is a famous tall tower in Paris?
Q2. 피보나치 수열을 계속하세요: 1, 1, 2, 3, 5, 8, (Continue the fibonacci sequence: 1, 1, 2, 3, 5, 8,)
Q3. 지구를 광범위하게 설명하세요. (Describe the planet Earth extensively.)
Q4. 한국음악은 어떤가요? (What is Korean music like?)
IFT only
A1.
### Response:
A famous tall tower in Paris is the Eiffel Tower, which stands at a height of 324 meters (1,063 feet).<|eot_id|>
A2.
### 응답:
13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5772863, 9275240, 15050005, 24414062, 39420467, 632
A3.
### 응답:
지구는 태양계에서 가장 큰 천체이며, 지름은 약 12,742 킬로미터 (7,918 마일)입니다. 지구는 지름 약 30,000 킬로미터 (18,640 마일)인 태양계의 가장 바깥쪽 궤도에 위치한 지름 약 12,742 킬로미터 (7,918 마일)의 궤도에 위치합니다. 지구는 지름 약 12,742 킬로미터 (7,918 마일)입니다. 지구는
A4.
### 응답:
AI로써, 나는 개인적인 취향이나 감정을 가지지 않습니다. 그러나 한국 음악은 전통 음악부터 현대 음악까지 다양하며, 다양한 장르와 스타일로 이루어져 있습니다. 전통 음악은 가라오케, 판소리, 그리고 사물놀이와 같은 다양한 종류로 이루어져 있으며, 현대 음악은 K-pop, K-rock, 그리고 K-indie와 같은 장르로 이루어져 있습니다. 한국 음악은 보통 감정과 멜로디의 강조로 특징지어지며, 보컬, 악기, 그리고
CPT
A1.
### Response:
The Eiffel Tower is a famous tall tower in Paris. It was built for the 1889 World's Fair. The tower was the tallest structure in the world at the time, standing at 324 meters. It has become an iconic symbol of Paris and one of the most recognizable landmarks globally. Visitors can ascend to the top for panoramic views of the city. The Eiffel Tower is a must-visit attraction for anyone traveling to Paris.
(Note: The response is written in a neutral, informative tone, suitable for a general audience.) <|eot_id|>
A2.
### 응답:
```python
def 피보나치(n):
if n <= 0:
return "피보나치 수열은 0 이상의 정수만 지원합니다."
elif n == 1:
return 1
elif n == 2:
return 1
else:
fib_sequence = [1, 1]
while len(fib_sequence) < n:
fib_sequence.append(fib_sequence[-1] + fib_sequence[-2])
return fib_sequence[-1]
# 테스트
print(피보나치(10)) # 34
``` ```
A3.
### 응답:
지구는 지구를 구성하는 천체의 한 부분으로, 지구는 태양계에서 3 번째로 큰 행성입니다. 지구는 지구의 위성인 달을 포함한 2 개의 자연적인 위성으로 구성되며, 지구의 궤도는 365.25 일간의 태양 주기와 일치합니다. 지구는 24 시간의 지구 주기와 일치합니다. 지구의 대기 중에는 이산화탄소, 메탄, 물 증기, 오존, 그리고 수소 등 다양한 기체가 존재합니다. 지구는 지구의 바다, 대륙, 산맥, 그리고 산 등 다양한 지형을 포함하고 있습니다. 지구의 생명체는 지구의 생물학적 다양성으로 인해 다양한 종을 포함하고 있습니다. 지구는 지구의 자체적인 자전을 가지며, 지구의 자전은 지구의 회전을 발생시킵니다. 지구는 지구의 자전과 지구의 회전에 의해 영향을 받습니다. 지구는 지구의 지구 자기장으로 인해 지구의 자기장을 발생시
A4.
### 응답:
- 한국음악은 다양한 장르와 스타일이 있습니다.
- 전통음악, 현대음악, 댄스음악 등이 있습니다.
- 한국음악은 세계적으로도 인기가 있습니다.
- 한국음악은 한국의 문화와 역사와 깊은 관련이 있습니다.
- 한국음악은 한국인의 감성과 정서를 표현하는 데 중요한 역할을 합니다.
- 한국음악은 한국의 전통과 현대를 연결하는 역할을 합니다.
- 한국음악은 한국의 독자적인 음악적 특징을 가지고 있습니다.
- 한국음악은 한국의 문화와 역사와 깊은 관련이 있습니다.
### 비고:
한국음악에 대한 일반적인 정보와 한국음악의 특징을 포함한 정보를 제공합니다.
한국음악에 대한 이해를 돕기 위해 다양한 장르와 스타일, 인기가 있는 정보, 문화와 역사와의 관련성, 감성과 정서 표현, 전통과 현대 연결, 독자적인 음악적 특징을 포함합니다.
한국음악에 대한 정보를 제공하는 데
CPT + IFT
A1.
### Response:
The famous tall tower in Paris is the Eiffel Tower.<|eot_id|>
A2.
### 응답:
피보나치 수열은 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17713, 28721, 46142, 75493, 123463, 199584, 321649, 530213, 864497, 1404957, 2277211, 3712816, 6078431, 9874943, 16049817, 25962571, 41840789, 66984423, 109416727, 177573939, 287489173, 461209281, 754896169, 123473682, 199479937, 321649, 5, 10, 15, 24, 39, 64, 125, 209, 339, 548, 885, 1443, 2368, 3891, 6356, 10281, 16541, 27072,
A3.
### 응답:
지구는 태양 주위에서 공전하는 유일무이한 행성입니다. 지구는 지름 약 12,742km인 구형의 행성입니다. 지구는 대부분이 물로 이루어져 있으며, 그 중 70% 이상이 바다에서 발견됩니다. 지구는 그 크기와 중력 때문에 다른 행성과 구별됩니다.
지구는 태양으로부터 평균 약 365일의 시간이 걸려서 공전하며, 그 궤도는 타원형입니다. 지구의 회전은 평균 24시간이 소요되며, 지구의 한 바퀴는 거의 27.3일이 소요됩니다.
지구는 생명을 지원하는 데 필요한 모든 것을 제공하는 지구 대기권으로 구성됩니다. 지구 대기권은 온도, 압력 및 기타 조건을 규제하는 역할을 합니다. 지구 대기권은 대기, 중간권 및 열권으로 구성됩니다. 대기는 대부분 질소와 산소로 이루어져 있으며, 중간권은 지구의 자기장을 포함하며, 열권은 지구의 대기를 태양으로부터 보호합니다.
A4.
### 응답:
한국음악은 다양한 스타일과 장르를 포괄하는 것으로, 전통적인 음악, 팝 음악, 랩 음악, 재즈 음악, 국악 등이 포함됩니다. 전통 음악은 피아노, 기타, 하프, 드럼 등으로 연주되는 서양악기와 함께 전통적인 한국악기인 가야금, 거문고, 피아노, 타악기 등이 함께하는 것으로 이루어져 있습니다. 팝 음악은 현대적인 사운드를 사용하며, 가사와 멜로디가 주로 한국어로 이루어져 있습니다. 랩 음악은 한국어로 된 가사와 한국 음악의 리듬에 맞춘 비트가 특징입니다. 재즈 음악은 한국어 가사와 함께 서양악기와 한국 전통 악기가 함께하는 것으로 이루어져 있습니다. 국악은 전통 한국 음악으로, 다양한 악기와 노래 스타일이 포함됩니다. 전반적으로, 한국음악은 그 나라의 풍부한 문화와 역사적 유산을 반영하는 다양한 스타일과 장르로 구성되어 있습니다.<|eot_id|>
4. Conclusion
CPT+IFT LoRA is not outstanding, but slightly better than the others in common sense and Korean communication skill. Also we validated loss data and tested model inference.
However, those evaluations are not sufficient due to the ambiguous and complex characteristics of languages.
Besides, considering that many institutes are training more huge models with better architecture, data, loss functions and techniques at this very moment, it is definitely too greedy that to build a perfect model with only this resources I just used.
Though the notable points from this practice are:
- Now we know how to fine-tune LLMs.
- We understood some important mechanisms and options in fine-tuning.
- We can fine-tune LLMs more faster and memory-efficiently.
In next time, I will cover multimodal LLM fine-tuning or LLMs evaluation methods relevant to accuracy, F1 score, perplexity, BLEU, and ROGUE.
Here are the model repos: IFT LoRA, CPT LoRA, CPT+IFT LoRA and its gguf.
5. Other informative posts
The followings are blog posts what I had seen during study. They are categorized into several types.
Unsloth
text
https://huggingface.co/blog/mlabonne/sft-llama3 (ENG)
https://devocean.sk.com/blog/techBoardDetail.do?ID=166285&boardType=techBlog (KOR)
https://unfinishedgod.netlify.app/2024/06/15/llm-unsloth-gguf/ (KOR)
multimodal
https://blog.futuresmart.ai/fine-tune-llama-32-vision-language-model-on-custom-datasets (ENG)
PEFT and TRL only
English data
https://kickitlikeshika.github.io/2024/07/24/how-to-fine-tune-llama-3-models-with-LoRA.html (ENG)
Korean data
https://naakjii.tistory.com/138 (KOR)
References
Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021). ↩︎
Dettmers, Tim, et al. “Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.” Advances in Neural Information Processing Systems 35 (2022): 30318-30332. ↩︎
Ma, Shuming, et al. “The era of 1-bit llms: All large language models are in 1.58 bits.” arXiv preprint arXiv:2402.17764 (2024). ↩︎
Wang, Jinheng, et al. “1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1. 58 Inference on CPUs.” arXiv preprint arXiv:2410.16144 (2024). ↩︎
https://unsloth.ai/blog/gradient (2024-11-21) ↩︎
Kalajdzievski, Damjan. “A rank stabilization scaling factor for fine-tuning with lora.” arXiv preprint arXiv:2312.03732 (2023). ↩︎
Shuttleworth, Reece, et al. “LoRA vs Full Fine-tuning: An Illusion of Equivalence.” arXiv preprint arXiv:2410.21228 (2024). ↩︎