Here comes a new challenger... And his name is DeepSeek!
review DeepSeek-R1 paper.
![]() The official DeepSeek logo
The official DeepSeek logo
Intro
DeepSeek, the small startup in China, recently released a reasoning specialized large language model DeepSeek-R1, and it matches or even beats ChatGPT o1 on the several benchmarks! In this post, we are going to briefly take a look DeepSeek-R1, then compare to GPT and LLaMA.
Index
- The importances
- How DeepSeek-R1 is trained?
- What is different between R1 and R1-Zero?
- The training concept of R1
- Compare to GPT and LLaMA
- R1 and its distilled small models
- References
1. The importances
Before the detail technical explanation, why the emergence of DeepSeek-R1 is so sensational?
- Though the developement cost of DeepSeek-R1 was smaller than ChatGPT o1 at least 1/20 times, DeepSeek-R1 matches ChatGPT o1. 1,2
- Despite of The US government chip curbs to CCP and the relative lack of AI accelerators compared to big tech companies in America, an unknown Chinese startup acheived such performance.
- Unlike OpenAI to close their techniques and codes, DeepSeek opened their training methods and models.
Then, how DeepSeek-R1 could surpassed ChatGPT o1?
2. How DeepSeek-R1 is trained?
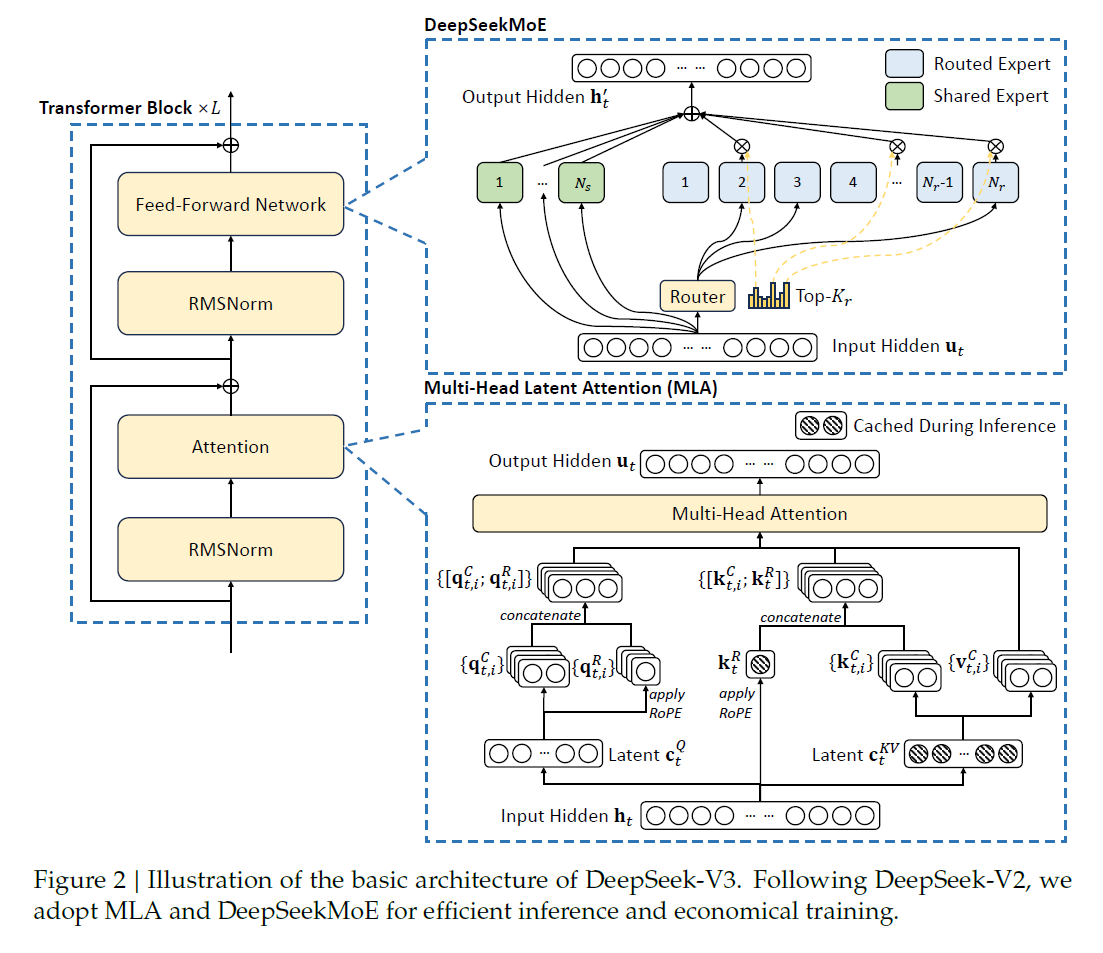 The basic architecture of V3, which is shared by R1 too.
The basic architecture of V3, which is shared by R1 too.
The architecture of R1 model is equivalent to V3, one of the latest language models of DeepSeek, since R1 shares the pre-trained DeepSeek-V3-base checkpoint as the starting point with V3. Therefore R1 also has a variant of Mixture-of-Experts (MoE) and Multi-head Latent Attention (MLA) structure.
For details about V3, let us talk about it in next review.
What is different between R1 and R1-Zero?
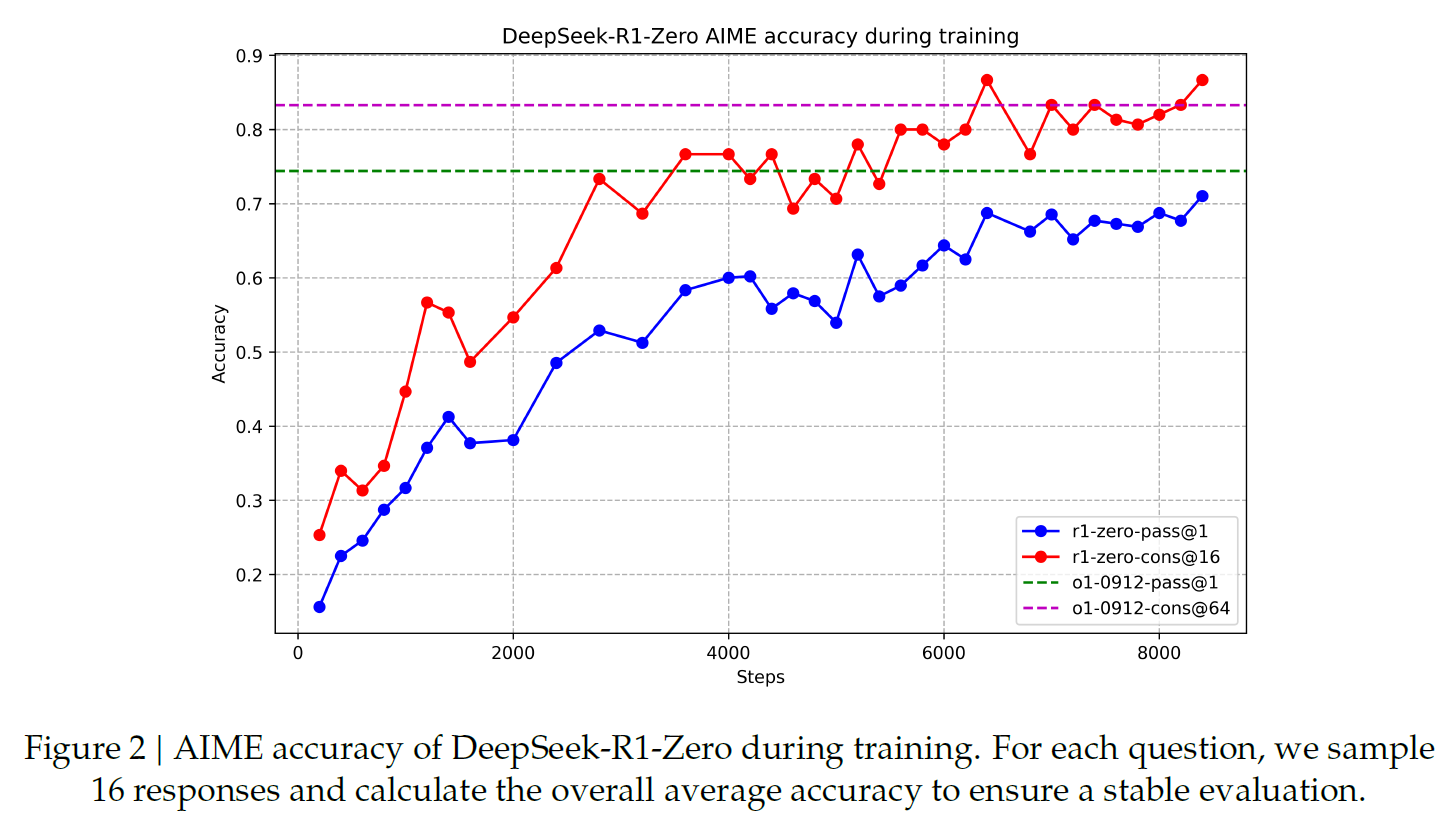 The perfomance comparision between R1-Zero and o1-0912. We can see that simple majority voting improves the perfomance.
The perfomance comparision between R1-Zero and o1-0912. We can see that simple majority voting improves the perfomance.
In the official R1 paper, the authors introduced both R1-Zero and R1.
R1-Zero is only trained by Group Relative Policy Optimization (GRPO), the reinforcement learning algorithm introduced first in DeepSeek-Math 3, with rule-based reward model (i.e., non-neural network reward model), without any additional supervised fine-tuning method. This RM evaluates 2 rewards types, accuracy rewards for correct answer and format rewards for placing thinking process in specific formatting tags.
Interestingly, R1-Zero tends to generate longer responses during training as the training steps increased. i.e., it spends more and more time for reasoning. This phenomenon is not caused from any explicit outer-side manipulations, but model’s self-improvement tendency to leverage test-time computation.
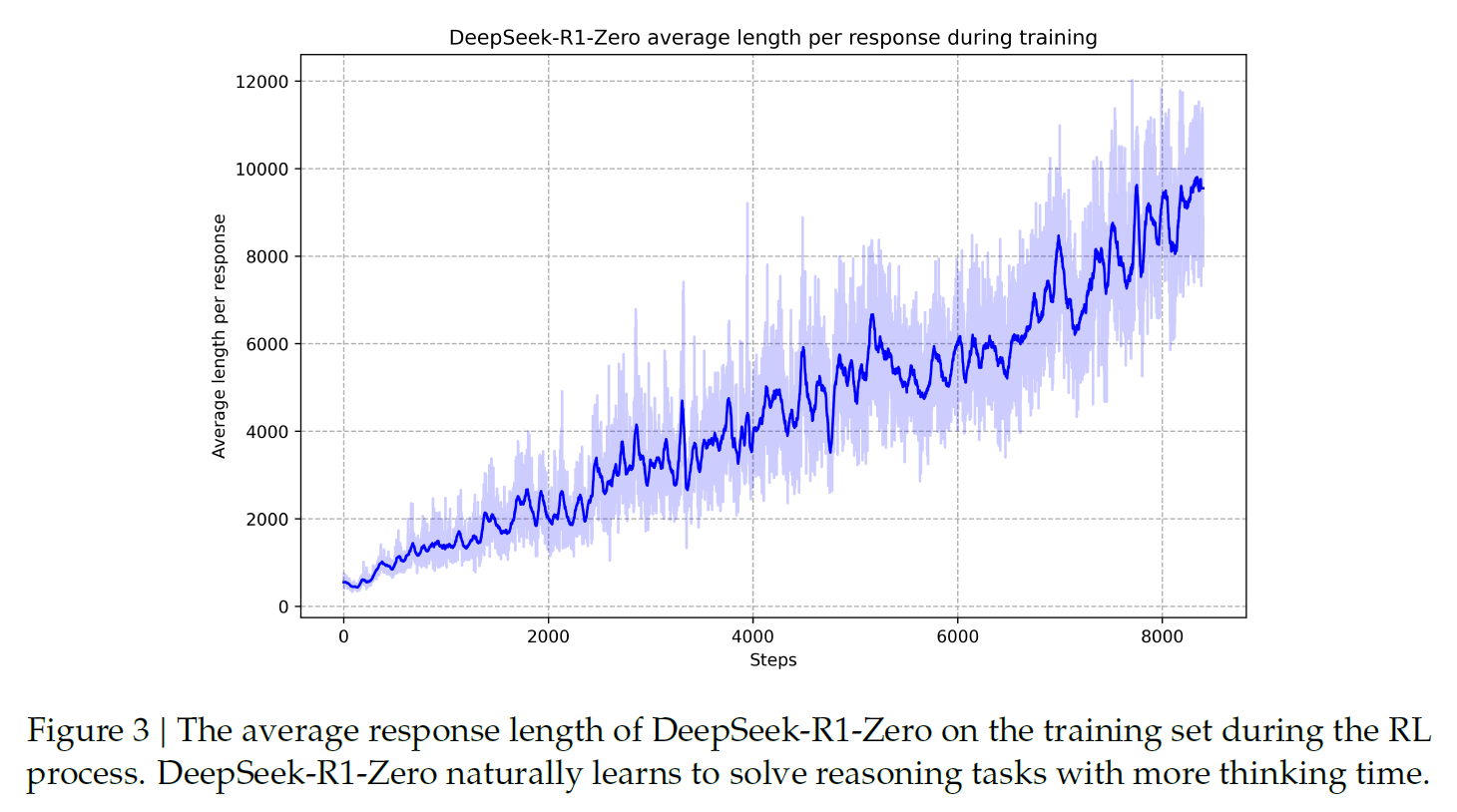 Increasing response length.
Increasing response length.
Although R1-Zero demonstrated competitive performance compared to OpenAI-o1-0912, it struggles with several issues such as poor readability, and language mixing.
To handle this drawbacks, the authors adopted additional techniques like cold-start fine-tuining and rejection sampling method.
The training concept of R1
From the results of R1-Zero, these 2 new goals are arised:
- Accelerate convergence and improve the performance by incorporating a small amount of high-quality data as cold-start.
- Keep coherence in Chains of Thought (CoT) as well as retain general capabilities to build an accessible model to everyone.
So they operated the following procedure for R1, the refined and reused version of R1-Zero and V3 pipelines:
- Fine-tune a V3-Base model with a small amount of long CoT data.
- Apply the same RL framework with one more additional reward: language consistency reward.
- In this step, they perfomed rejection sampling from the model, and then restart fine-tuning another pre-trained V3-Base model from scratch. In detail,
- Collect 600k reasoning samples by curating reasoning prompts assisted by DeepSeek-V3 and filtering out poor some of them. choose only the correct ones from multiple responses for each prompt. (This is rejection sampling.)
- Collect 200k non-reasoning samples from (1) SFT dataset of V3 and (2) generated CoT responses from V3 by prompting.
- Perform a secondary RL, especially to improve both model helpfulness and harmlessness.
Compare to GPT and LLaMA
In this section, we compare the alignment strategies of GPT, LLaMA, and DeepSeek respectively.
GPT’s Reinforcement Learning from Human Feedback (RLHF) 4
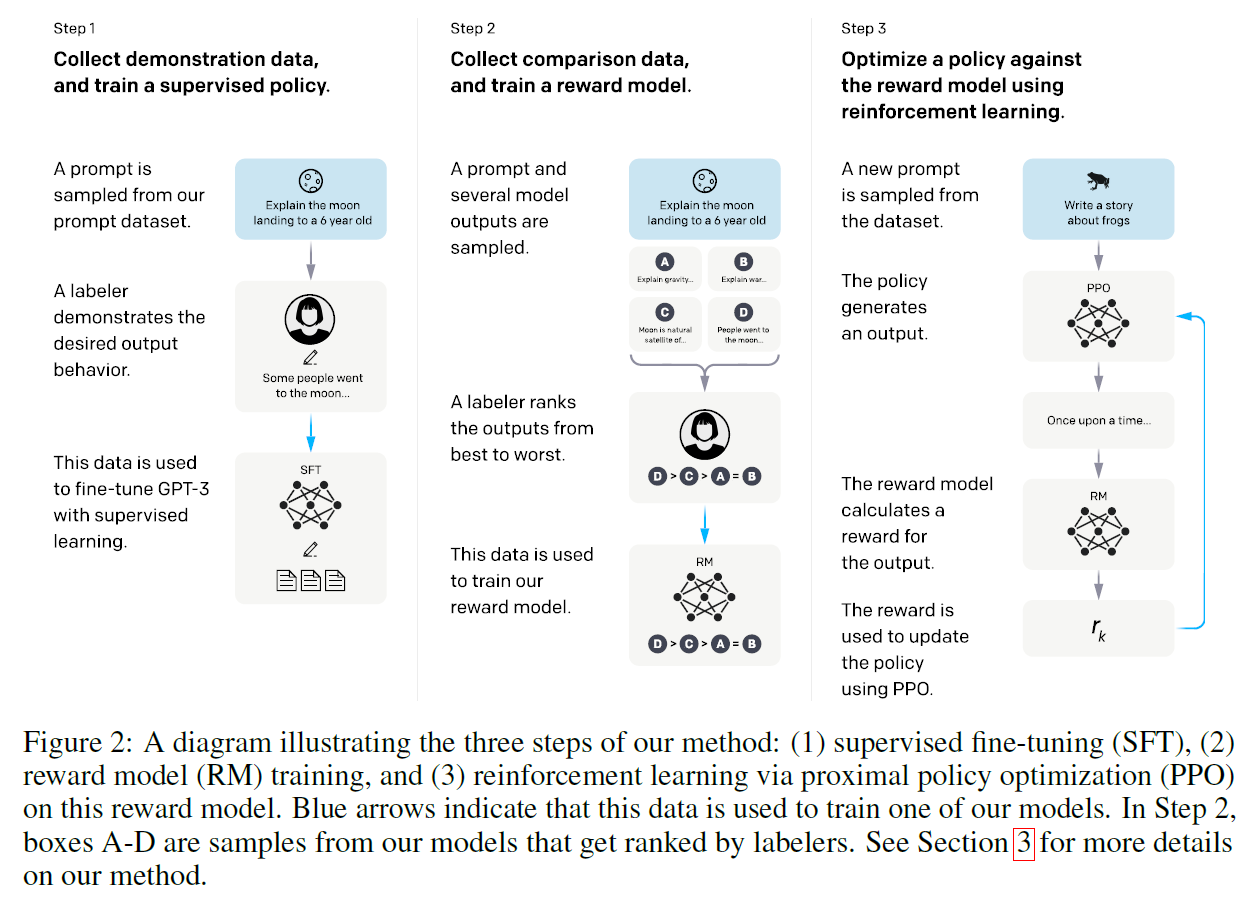 RLHF of InstructGPT (2022)
RLHF of InstructGPT (2022)
RLHF is consist of the following 3 steps:
1. Perform supervised fine-tuning on GPT3.
2. Train a reward model (RM)
For each prompt, rank \(K\) = 4 to 9 responses and produce \({K \choose 2}\) comparisons. Rather than shuffle the total comparisons, group them by each prompt into a mini-batch to avoid overfitting.
The loss function for the RM is: \[L(\phi) = - \frac{1}{K \choose 2} \mathbb{E}_{(x, y_w, y_l)~D} [\log(\sigma(r_{\phi}(x, y_w) - r_{\phi}(x, y_l)))]\]
where \(r_{\phi}(x, y)\) is the scalar reward output for \((x,y)\), \(y_w\) and \(y_l\) are preferred and unpreferred completion, and \(D\) is the human comparisons dataset.
3. Reinforcement learning via proximal policy optimization (PPO)
The RL objective for the language model is: \[L_{PPO_{ptx}}(\pi_{\theta}; \pi_{ref}) = -\mathbb{E}_{(x, y) \sim D_{\pi_{\theta}}}\left[r_{\phi}(x, y) - \beta\log\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)}\right] - \gamma\mathbb{E}_{x \sim D_{pretrain}}\left[\log(\pi_{\theta}(x))\right]\]
where \(\pi_{\theta}\) is the learned RL policy, \(\pi_{ref}\) is the supervised model, and \(D_{pretrain}\) is the data distribution from pretraining. \(\beta\) and \(\gamma\) are coefficients for KL penalty and pretraining respectively. The KL penalty \(\pi_{\theta}(y|x)\log(\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)})\) regulates \(\pi_{\theta}\) to follow \(\pi_{ref}\). Meanwhile, the pretraining loss term is a cross-entropy loss that prevents the current model to forget general ability obtained during pretraining, so it is an auxiliary loss of InstructGPT.
Steps 2 and 3 can be iterated continuously together.
LLaMA’s Direct Preference Optimization (DPO) 5
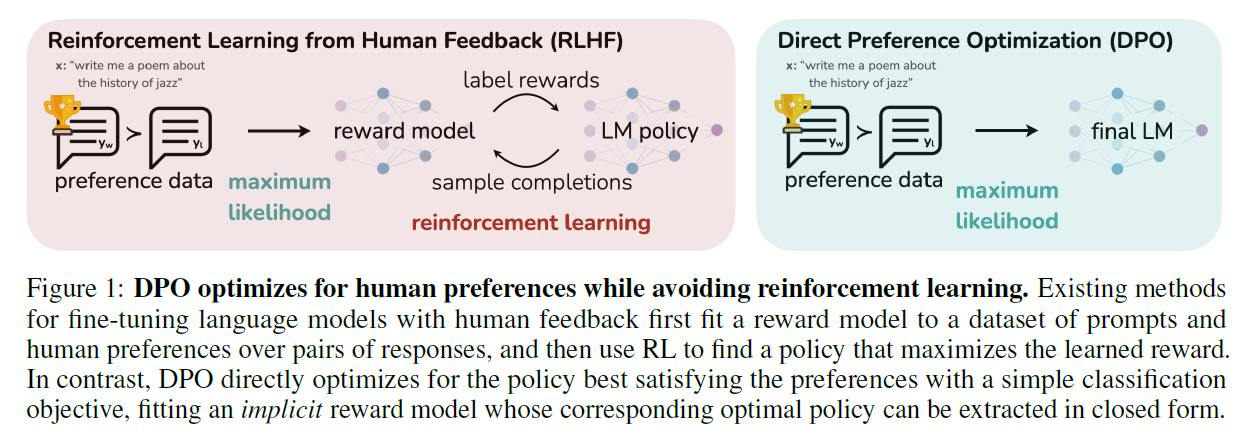 RLHF vs. DPO
RLHF vs. DPO
Instead of optimization loop like RLHF, the research team extracts the optimal policy in closed form by RM parameterization. (i.e., a loss function over reward functions \(\rightarrow\) a loss function over policies)
By parameterization, the research derived the following policy objective: \[L_{DPO}(\pi_{\theta};\pi_{ref}) = -\mathbb{E}_{(x, y_w, y_l) \sim D}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)} - \beta\log\frac{\pi_{\theta}(y_l|x)}{\pi_{ref}(y_l|x)}\right)\right].\]
Let us derive the gradient to understand the dynamic of DPO. Since \(\hat{r_{\theta}}(x, y) = \beta\log\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)},\) from a variable substitution \(\Delta=\hat{r_{\theta}}(x, y_w)-\hat{r_{\theta}}(x, y_l), \quad L = -\log\sigma(\Delta)\) and \[\begin{aligned} \frac{dL}{d\Delta} &= \frac{-1}{\sigma(\Delta)}\sigma^{\prime}(\Delta) \newline &= \frac{-1}{\sigma(\Delta)}\sigma(\Delta)(1-\sigma(\Delta)) \newline &= -(1-\sigma(\Delta)). \end{aligned}\]
Therefore, \(\sigma(\Delta) \rightarrow 1, \frac{dL}{d\Delta} \rightarrow 0.\)
i.e., if \(\hat{r_{\theta}}(x, y_w) >> \hat{r_{\theta}}(x, y_l)\), the loss changes slowly.
On the other hand, \(\sigma(\Delta) \rightarrow 0, \frac{dL}{d\Delta} \rightarrow -1.\)
i.e., if \(\hat{r_{\theta}}(x, y_l) >> \hat{r_{\theta}}(x, y_w)\), the loss changes rapidly.
Furthermore, apply the chain rule to the derivative w.r.t \(\theta.\) Then \[\begin{aligned} \frac{\partial{L}}{\partial{\theta}} &= \frac{\partial{L}}{\partial{\Delta}} \cdot \frac{\partial{\Delta}}{\partial{\theta}} \newline &= -(1 - \sigma(\Delta)) \cdot \left[\frac{\partial{\hat{r_{\theta}}(x, y_w)}}{\partial{\theta}} - \frac{\partial{\hat{r_{\theta}}(x, y_l)}}{\partial{\theta}} \right]. \end{aligned}\]
Since \(\hat{r_{\theta}}(x, y) = \beta\log\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)},\) when \(\frac{\partial{L}}{\partial{\theta}} < 0,\) this equation implies that the gradient update increases \(\hat{r_{\theta}}(x, y_w)\) and decreases \(\hat{r_{\theta}}(x, y_l),\) thereby boosting the likelihood of \(y_w\) and penalizing \(y_l\) simultaneously.
DeepSeek’s Group Relative Policy Optimization (GRPO) 6
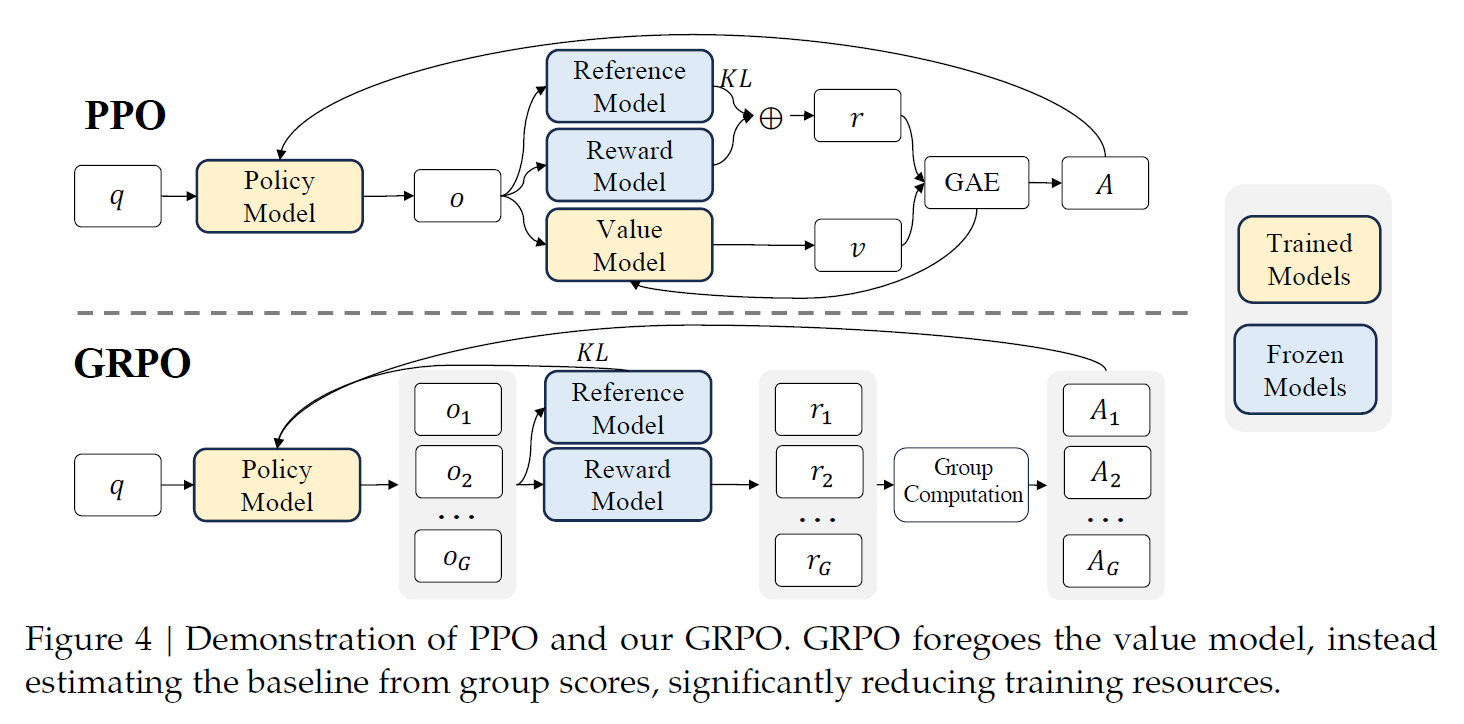 RLHF vs. GRPO
RLHF vs. GRPO
In PPO, an actor-critic RL algorithm, neural reward modeling may suffer from reward hacking and RL training loop needs abundant computational resources. So, DeepSeek adopts the following surrogate objective:
for each question \(q\) and the corresponding outputs \(\{ o_i \}^G_{i=1} \sim \pi_{\theta_{old}},\) \[\begin{gathered} L_{GRPO}(\theta) = -\mathbb{E}_{(q \sim P(Q), \{ o_i \}^G_{i=1} \sim \pi_{\theta_{old}(O|q)})} \frac{1}{G}\sum^G_{i=1}\left[\min\left[\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}A_i, Clip\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon\right)A_i\right] - \beta D_{KL}(\pi_{\theta}||\pi_{ref}) \right], \newline D_{KL}(\pi_{\theta}||\pi_{ref}) = \frac{\pi_{ref}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} -\log\frac{\pi_{ref}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} - 1, \end{gathered}\]
where \(\epsilon\) and \(\beta\) are hyperparameters, and the advantage \(A_i=\frac{r_i-mean(\{r_1, \dots, r_G\})}{std(\{r_1, \dots, r_G\})}\) with reward model outputs \({r_i} = r_{\varphi}(o_i).\)
As mentioned, this non-neural RM system calculates accuracy, format and language consistency rewards.
3. R1 and its distilled small models
Use DeepSeek-R1 immediately from chat.deepseek or refer to the official API doc.
If you are interested in running the model locally, visit huggingface repo. You can find not only the original safetensors, but also distilled version of R1 from LLaMA and Qwen. These open-source based models are only distilled from R1, but not trained by the RL framework.
References
https://www.reuters.com/technology/artificial-intelligence/chinese-chip-makers-cloud-providers-rush-embrace-homegrown-deepseek-2025-02-05/ ↩︎
https://time.com/7210875/deepseek-national-security-threat-tiktok/ (2025-02-06) ↩︎
Shao, Zhihong, et al. “Deepseekmath: Pushing the limits of mathematical reasoning in open language models.” arXiv preprint arXiv:2402.03300 (2024). ↩︎
Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in neural information processing systems 35 (2022): 27730-27744. (Refer to this arxiv.) ↩︎
Rafailov, Rafael, et al. “Direct preference optimization: Your language model is secretly a reward model.” Advances in Neural Information Processing Systems 36 (2024). (Refer to this arxiv.) ↩︎
Guo, Daya, et al. “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arXiv preprint arXiv:2501.12948 (2025). ↩︎