Large Language Models before ChatGPT 3.5
summarize the papers of GPT1, BERT, GPT3 and the scaling laws.
After the publication of “Attention Is All You Need”, a number of language models have chosen the transformer as their base structure. As a result, many powerful models have been derived from it, the most famous of which are the GPT models and BERT.
The Papers
1. GPT-1
The paper, “Improving Language Understanding by Generative Pre-Training (2018)” presents GPT-1.
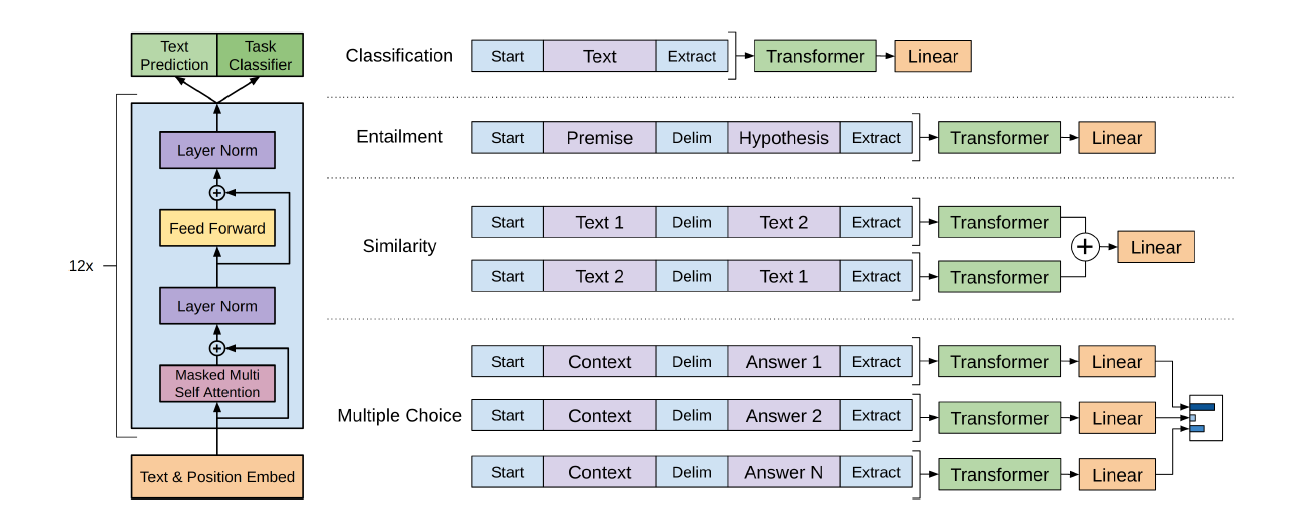 figure1: Transformer architecture and input transformations
figure1: Transformer architecture and input transformations
Characteristics
Architecture: multilayer transformer decoder (auto-regressive model)
- Training
- Unsupervised pre-traning
- for given corpus of tokens \(\mathcal{U} = \{u_1, \dots, u_n\}\) and the size of the context window \(k\), maximize the following log-likelihood: \(L_1(\mathcal{U}) = \sum_i \log P(u_i \vert u_{i-k}, \dots, u_{i-1}; \Theta)\).
- Supervised fine-tuning
- for labeled dataset \(C\) consisting of a sequence of input tokens \(\{x^1, \dots, x^m\}\) with a corresponding label \(y\), maximize the following log-likelihood: \(L_2(\mathcal{C}) = \sum_{(x,y)} \log P(y \vert x^1, \dots, x^m)\).
- In particular, include an auxilary objective in the fine-tuning to improve generalization and accelerate optimization: \(L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda * L_1(\mathcal{C})\).
- Unsupervised pre-traning
- Input Representation
- input data are transformed for each task like inference, similarity, question answering and reasoning.
- inference: judging the relationship between a pair of sentences from one of entailment, contradiction or neutral
- similarity: predicting whether 2 sentences are semantically equvalent or not
- examples: concatenate sentences and use a delimeter between them, change the order of sentence pairs (similarity), and group different answers with the same context and question (answering and reasoning).
- delimiter: a character that marks the beginning or end of a unit of data
- input data are transformed for each task like inference, similarity, question answering and reasoning.
- Significance
- The experiment results indicate that pre-trained layers have functionality for tasks like answering (RACE) and inference (MultiNLI).
- Without supervised fine-tuning, the model was able to perform tasks such as answering (RACE), classification (CoLA, SST-2) and DPRD (winograd schemas, identifying the antecedent of an ambiguous pronoun in a statement).
2. BERT
The paper, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)” introduces BERT.
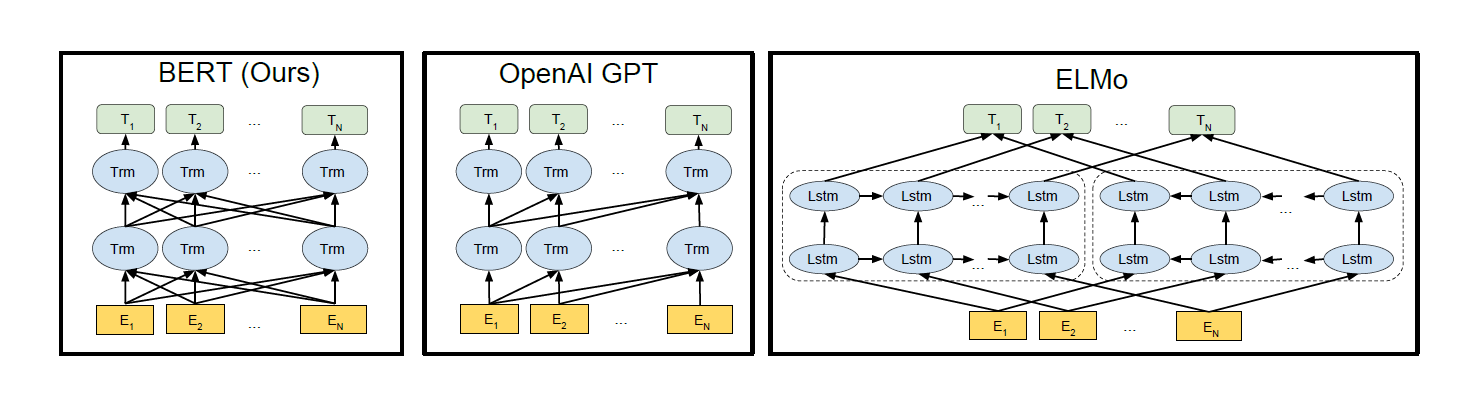 figure2: Differences in pre-training model architectures
figure2: Differences in pre-training model architectures
Characteristics
- Architecture: transformer encoder
- unlike GPT, BERT is designed to understand not only left-to-right context, but right-to-left one.
- Training
- BERT has its own training method and data input form, as well as pre-training and fine-tuning equivalent to GPT.
- Pre-training
- Masked Language Model (Cloze task)
- To prevent trivial prediction in the bidirectional model, the authors hide a certain percentage of arbitrary tokens in the input sequences.
- This masking is not applicable to fine-tuning, so (1) the training data generator randomly selects 15% of the token positions for prediction; (2) Then, for those tokens, replaces 80% of them with the [MASK] token and 10% of them with random tokens, and leave the remaining 10% unchanged.
- Next Sentence Prediction
- To train a model that handles answering and inference tasks, concatenate either actually consecutive or randomly sampled 2 sentences in a 50:50 ratio.
- Masked Language Model (Cloze task)
- Fine-tuning
- Thanks to the transformer structure, fine-tuning becomes a straightforward process, requiring only the adjustment of inputs and outputs for each specific task.
- for the input, sentence pairs in pre-training are analogous to downstream tasks such as classification and answering.
- for the output, use the token representations to token-level task and the [CLS] representation to classification task.
- Thanks to the transformer structure, fine-tuning becomes a straightforward process, requiring only the adjustment of inputs and outputs for each specific task.
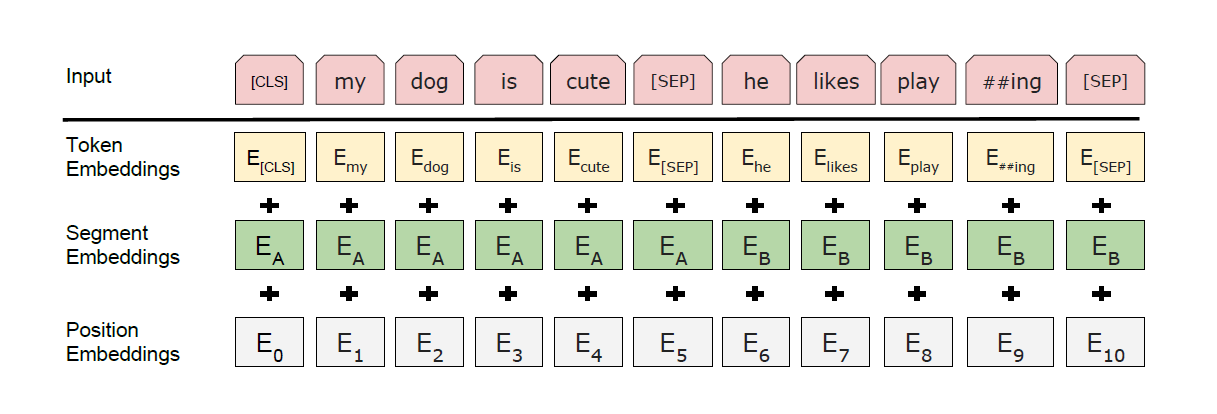 figure3: BERT input representation
figure3: BERT input representation
- Input&Output Representations
- One token sequence consists of either one sentence or a pair of sentences.
- Every first token of each sequence is always a special classification token [CLS], which is the final hidden state.
- The sentences in a sequence are separated by special delimiter token [SEP].
- A learned segment embedding indicates whether each token in a sequence belongs to the first or the last sentence.
- Input representation is denoted by the sum of word token, position and segment embeddings.
- Significance
- BERT showed better results than GPT-1 and the shallow concatenation of unidirectional models (ELMo) in token prediction within a text.
- The authors demonstrated that there is a proportional relationship between the size of the pre-trained bidirectional model and downstream performance.
3. Scaling Laws for NLMs
The paper, “Scaling Laws for Neural Language Models (2020)” explores power-laws for transformer-based language models.
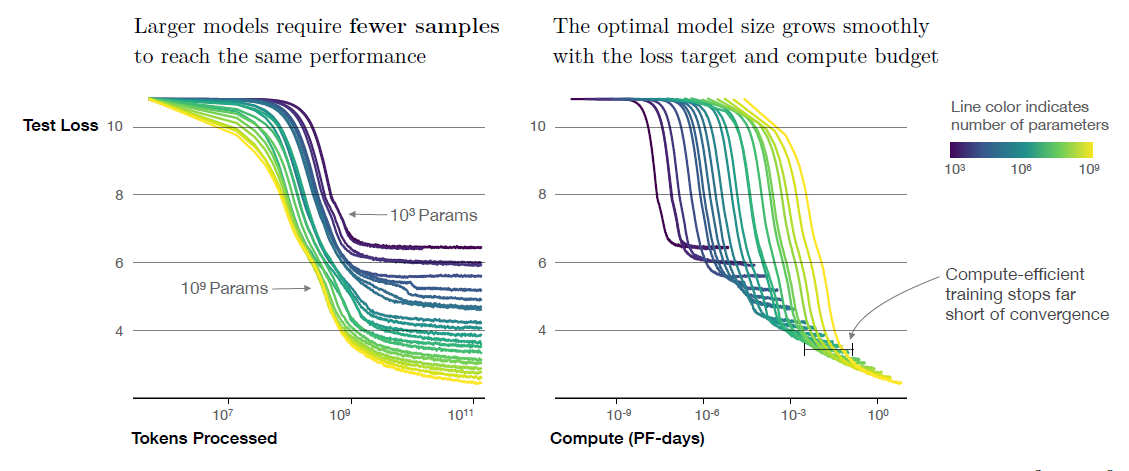 figure4: A series of language model training runs (excluding embeddings)
figure4: A series of language model training runs (excluding embeddings)
Summary
In this paper, the authors showed that there are empirical power laws for the cross-entropy loss of transformer-based auto-regressive language models training.
First of all, given an arbitrarily limited compute budget \(C\), the most important variable in model performance is the number of model parameters \(N\). The size of dataset \(D\) has less impact than \(N\) and the number of training steps \(S\) is negligible (where \(D=B*S\), \(B\): mini-batch size).
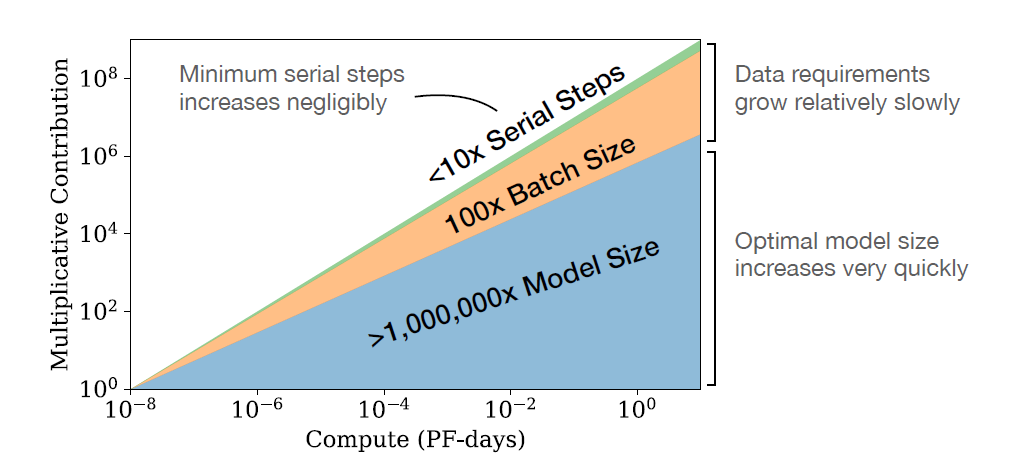 figure5: How to allocate resources
figure5: How to allocate resources
Other key points are as follows:
Performance depends strongly on scale, weakly on model shape such as residual, feed forward and attention heads.
Suppose that there are no restrictions on N,D and C. Then performance has a power law relationship with each of them.
Performance improves predictably as long as both N and D grow together.
No matter model scale, training curves follow power-laws.
Even if the validation set and an evaluation set are distributed differently, the model performances have very strong correlation.
Despite less \(D\) and \(S\), larger models were able to reach the same level of performance as smaller ones.
When \(N\) and \(D\), excluding \(C\) are restricted, it is efficient to appropriately stop training large models before convergence.
Only targeting loss has a quasi-power-law relationship with optimal mini-batch size. Also mini-batch size depends deterministically on the gradient noise scale.
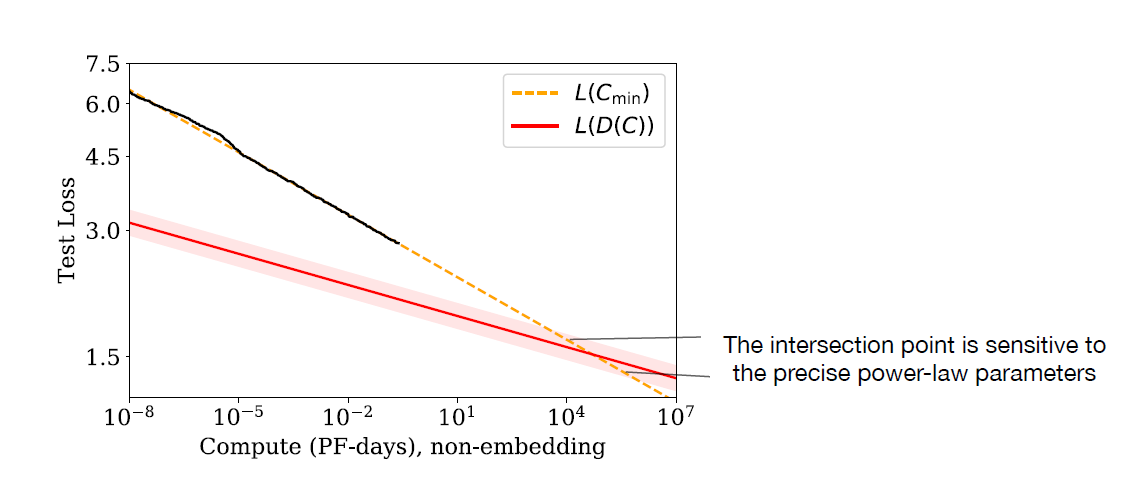 figure6: A contradiction
figure6: A contradiction
In addition, the authors mentioned a contradiction in 2 power-law relationships. To conclude, even if we perform compute-efficient training without data reuse, overfitting eventually occurs when comparing the asymptotes of the 2 relationships. The authors guess that the intersection between the asymptotes implies that transformer-based LMs will reach their maximal performance at the point. This point is \[\begin{gathered} C^* \sim 10^{4} \text{ PF-Days}, \quad N^* \sim 10^{12} \text{ parameters}, \quad D^* \sim 10^{12} \text{ tokens}, \quad L^* \sim 1.7 \text{ nats/token} \newline \text{where 1 PF-day} = 10^{15}\times24\times3600 = 8.64\times10^{19} \text{ floating point operations.} \end{gathered}\]
4. GPT-3
The paper, “Language Models are Few-Shot Learners (2020)” introduces GPT-3.
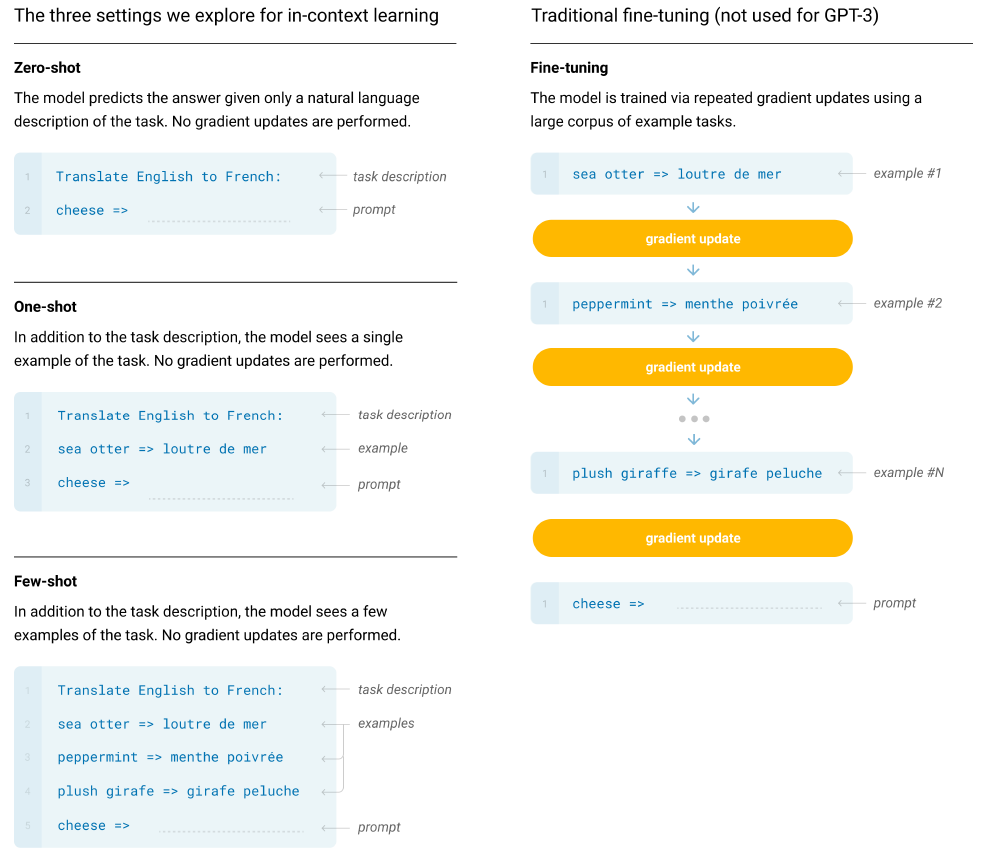 figure7: In context learning and fine-tuning
figure7: In context learning and fine-tuning
Characteristics
- Architecture
The GPT-3 architecture adopts alternating dense and locally banded sparse attention patterns in the transformer, as well as incorporates equivalent layers from GPT-2, such as modified initialization, pre-normalization layer, and reversible tokenization. Additionally, the authors parallelized the model in both depth and width directions across GPUs.
- Training
- As demonstrated in the scaling laws, larger model usually use larger mini-batch size and smaller learning rate.
- There are several different settings for evaluating GPT-3 after pre-training with SGD:
- Fine-tuning: Updating the parameters toward downstream tasks.
- ( )-shot learning: Performing in-context learning without weights update, with \(K\), \(1\) or \(0\) examples respectively.
- Among these settings, one-shot and zero-shot learning closely resemble human inference and learning. They are convenient, robust (performing well across domains without examples) and precise (avoiding spurious correlations).
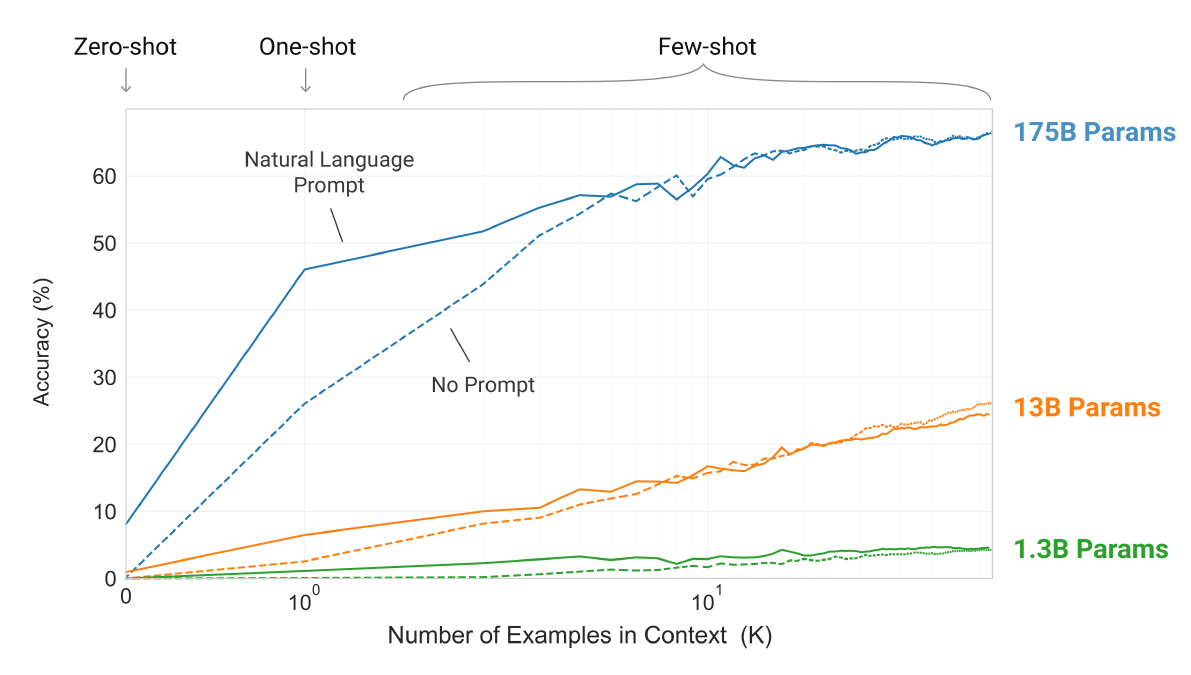 figure8: Larger models make increasingly efficient use of in-context information.
figure8: Larger models make increasingly efficient use of in-context information.
- Significance
- In most cases, few-shot outperformed one-shot, and one-shot outperformed zero-shot in evaluation performance. Moreover, this performance gap widened with the scaling up of the model size.
- GPT generally performed worse than fine-tuned SOTA models; however, it is noteworthy that GPT demonstrated impressive performance close to them without any additional parameter training.
- When examining data contamination (train-test overlap) post-training, the effect is negligible in most cases.
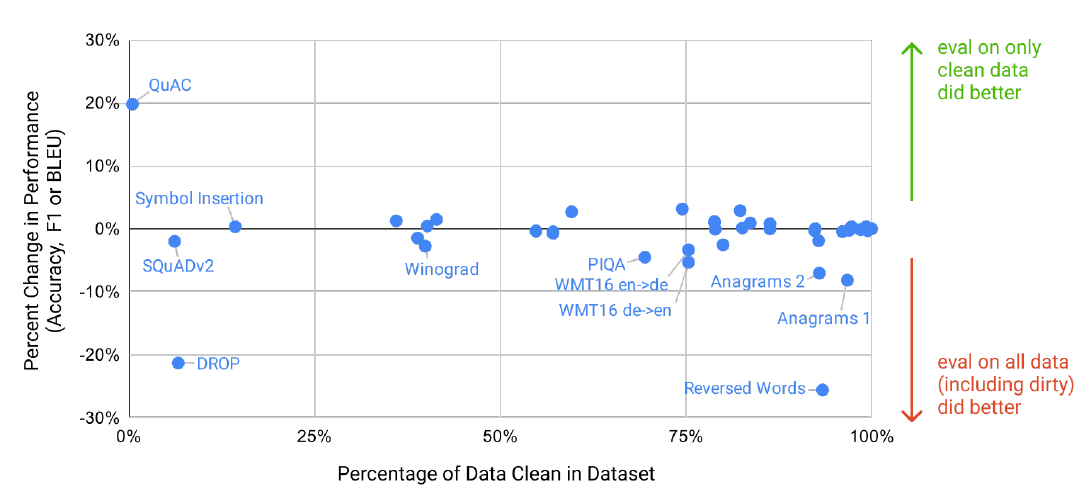 figure9: Benchmark contamination analysis
figure9: Benchmark contamination analysis
- Limitation
- GPT-3 exhibits occasional loss of coherence, logical inconsistencies, self-contradictions and semantic repetition in generated text.
- A more fundamental limitaion lies in the pre-training objective; It weights every token equivalently and focuses on simple prediction rather than goal-directed approach.
- The model lacks context recognization of the world, such as video or real-world physical interaction.
- GPT-3 is still trained on much more text than a human experiences in a lifetime.
- It is ambiguous that whether few-shot learning involves learning from scratch or mimics actions from pre-training during actual testing, i.e., raising questions about the existence of meta-learning characteristic.
- Scaling-up may be inefficient in practical inference.
- Like other DL models, decisions from GPT-3 are not easy to interpret.
Extra: GPT-2 code
Here is the open source code of GPT-2.
- Architecture
- As mentioned in GPT-3, one of the distinctive modifications in GPT-2, when compared to the original transformer, involves the order of layer normalization in each decoder block.
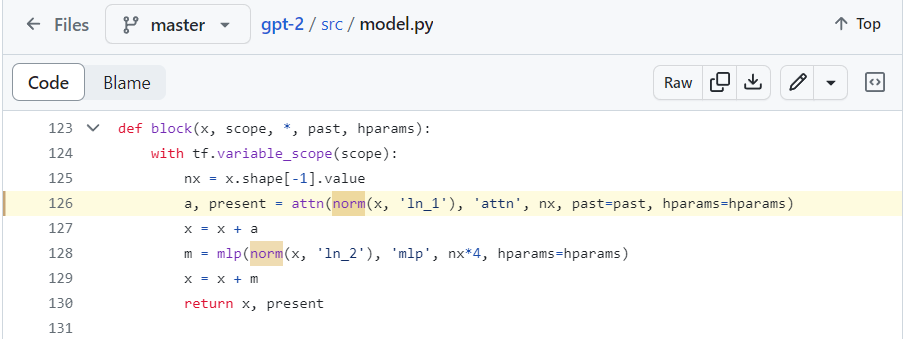 figure10: One of modifications
figure10: One of modifications
- Algorithm
- There are 2 important algorithms to train GPT models.
- Nucleus Sampling
- To sample a token from the estimated distribution of vocabulary, first, GPT-2 selects top \(K\) candidate tokens of higher probability. After then the model pick one token from a sub-group of the candidates, where the cumulative probabilities are less or equal to \(P\).
- In this procedure, the model uses logit instead of probability since \(p \in [0, 1]\) and \(logit(p) = \log(\frac{p}{1-p}) \in (-\inf, \inf)\).
- For details, it would be helpful to read this post.
- Byte Pair Encoding
- A tokenization algorithm that starting from character level, repeats merging the most frequent pairs of characters or sub-words until pre-fixed vocabulary number to produce units of a language data.
- It is proper to pre-tokenized (i.e., having word spacing) languages such as English.
- For details, I suggest you to refer to this post.
- Nucleus Sampling
- There are 2 important algorithms to train GPT models.
References
[1] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
[2] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
[4] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. (visit here)